
Hey there, fellow data enthusiast! Have you ever hit a wall trying to scrape a website only to find out Akamai protects it? Trust me, you’re not alone. In this article, we’ll explore the ins and outs of Akamai’s defenses and, more importantly, show you how to get around them easily.
How Does Akamai Work?
Akamai is a cloud delivery service that uses many techniques to block bots and prevent internet threats. It provides a layer of security that can be particularly challenging for web scrapers to navigate.
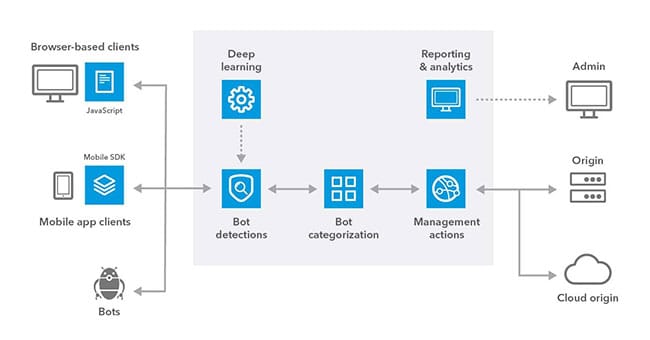
Here’s a breakdown of how Akamai works and why it’s such a formidable challenge.
IP Blocks
Akamai limits the request volume a client can send to a server within a particular period. Once you exceed that limit, it flags your request as a bot and deploys its bot management system to block your IP from making subsequent requests.
Depending on the website’s policies, the IP block could be short or long-term, or worse, it could last forever.
HTTP Request Details
Your HTTP request details can reveal more information than you could imagine. They provide insights into the request protocol (HTTP1.1 or HTTP2), method, body, query strings, and headers.
Akamai’s bot manager scans those against the expected request baseline and returns a bot score to determine whether the request is automated or from a human. It then mitigates requests with a high bot score by blocking them immediately or prompting them to solve a JavaScript challenge.
TLS Fingerprinting
Akamai uses TLS fingerprinting to validate the communication between two web resources. It does so by checking for the details in the TLS handshake between the client and the server. The TLS handshake details the client’s supported TLS version, accepted encryptions, server name indication (SNI), compression type, and more.
Automated bots, like scrapers, need to simulate these details to pass the fingerprinting challenge. Otherwise, the system can detect slight inconsistencies in the TLS handshake and block any request that doesn’t comply with the expected parameters.
Browser Fingerprinting
Another blocking measure used is to gather information about users from their browser fingerprints. Browser fingerprinting is a technique for uniquely identifying your device on the internet.
It details your client type, installed software, timezone and browsing history, keyboard layout, web workers, navigation and click patterns, and many more. Since this information is unique to each user, the system leverages it to detect and block bots by catching deviations from the expected browsing behavior.
Overcoming Akamai
Bypassing Akamai isn’t a walk in the park, but it’s not mission impossible either. Here are some proven techniques to increase your chances:
Simulating User Behavior with Headless Browsers
Headless browsers can mimic regular user behavior, helping you stay under Akamai’s radar. These browsers operate without a graphical user interface, executing JavaScript and handling cookies just like a real browser. This way, they can simulate human-like browsing behavior that’s less likely to raise red flags.
Using Stealth Plugins
Stealth plugins help you fly under the radar by disguising your scraping activities. They can modify the browser’s fingerprint data and other identifiable information, making your bot appear more like a regular user. Plugins like Puppeteer Extra’s stealth plugin can significantly affect evading detection.
Integrating Rotating Residential Proxies
Rotating residential proxies changes your IP addresses frequently, making it harder for Akamai to block you. These proxies use real residential IP addresses, so your requests appear to come from genuine users. Tools like Bright Data or Smartproxy can help you integrate rotating proxies into your scraping setup, enhancing your anonymity.
Optimizing Request Headers
Mimicking regular HTTP requests by optimizing your headers can help you avoid detection. This involves tweaking your user-agent strings, referrers, and other header fields to match those expected from real browsers. Tools like Scrapy and BeautifulSoup provide options to customize request headers easily.
Limitations and Considerations
Even with these techniques, Akamai is constantly evolving. Combining methods doesn’t guarantee full-proof success but can significantly improve your chances. The blocking measures and detection algorithms become more sophisticated over time, and scraping attempts must adapt accordingly.
The Easy Way – Web Scraping APIs:
Sometimes, it’s wiser to let specialized tools handle the heavy lifting. That’s where web scraping APIs come into play, designed to bypass the Akamai Bot Manager and other anti-scraping systems effortlessly. Solutions like ZenRows handle everything for you—managing request headers, rotating premium proxies, and using AI to dodge anti-bot barriers.
This allows you to skip the complicated steps we’ve discussed and concentrate fully on your data extraction logic.
1. ZenRows
ZenRows is a top-tier web scraping API renowned for its effectiveness in tackling the toughest of scrapes, including those protected by Akamai. It acts like a ninja, stealthily bypassing Akamai’s defenses to extract the data you need.
Features:
- Headless Browser: Simulates real user behavior, bypassing browser detection measures.
- Proxy Rotation: Auto-rotates premium residential proxies to avoid IP blocks.
- Request Header Optimization: Mimics regular HTTP requests to stay undetected.
- Anti-CAPTCHA: Automatically solves CAPTCHAs to keep the scraping process smooth.
Ease of Use
ZenRows is compatible with any programming language and requires only one API call, making it super easy to use.
Use Case
Perfect for developers who need a reliable and straightforward solution without diving into technical details.
2. ScraperAPI
ScraperAPI is a versatile web scraping tool that handles IP rotation, CAPTCHAs, and browsers to get you the data you need.
Features
- Proxy Management: Automatic IP rotation and geo-targeting.
- Captcha Handling: Built-in solutions to bypass CAPTCHA challenges.
- Header Optimization: Customizable headers to mimic real browsers.
Ease of Use
Simple integration with multiple programming languages, including Python, Node.js, and more.
Use Case
Ideal for users who require geo-targeted data and frequent scrapes.
3. Octoparse
Octoparse offers a visual web scraping tool that simplifies data extraction with an intuitive, point-and-click interface.
Features
- Visual Scraping: No coding required—just point and click to set up your scraping tasks.
- Cloud-based Scraping: Run your scrapes in the cloud for faster and more reliable data extraction.
- IP Rotation and Anti-blocking Measures: Built-in solutions to prevent IP bans and CAPTCHAs.
Ease of Use
User-friendly interface, perfect for non-developers and those new to web scraping.
Use Case
Great for business users and analysts who need a no-code solution for regular data extraction.
4. Bright Data
Bright Data is known for its extensive proxy network and powerful scraping capabilities, making it a popular choice for large-scale data extraction.
Features
- Extensive Proxy Network: Access to millions of residential, mobile, and datacenter IPs.
- CAPTCHA Solving: Automated solutions for overcoming CAPTCHA challenges.
- Data Collection Automation: Advanced tools to automate data collection and processing.
Ease of Use
Robust API with comprehensive documentation and support for multiple programming languages.
Use Case
Built for enterprises that need reliable, scalable scraping solutions.
5. Scrapy (with Crawlera):
Scrapy is an open-source web crawling framework, and when paired with Crawlera, it becomes a powerful tool for bypassing anti-scraping mechanisms
Features
- Smart Proxy Management: Crawlera rotates proxies and manages IPs to minimize blocks.
- Customizable Scraping: Full control over your scraping logic and data extraction process.
- JavaScript Rendering: Handles JavaScript-heavy websites effortlessly.
Ease of Use
Requires some coding knowledge but offers extensive flexibility and control.
Use Case
Ideal for developers who need a powerful, customizable scraping framework integrated with professional proxy management.
Conclusion
By now, you should have a solid understanding of how Akamai works and the advanced techniques required to bypass its defenses. While traditional methods like headless browsers and proxy rotation can help, a dedicated web scraping API is undoubtedly the most reliable and efficient solution. After trying different scraping APIs, ZenRows leads as the most effective solution for extracting data from any website without getting blocked.. Don’t just take our word for it—try out these tools and see for yourself how seamless web scraping can be. Happy scraping!








