

Three APIs returning JSON, a scraper dumping raw HTML, a vendor that emails CSV exports every Tuesday, and an XML feed nobody’s touched since 2021. All of it needs to end up in one place, in one shape, ready for whatever analytics or ML pipeline sits downstream. That’s the multi-format pipeline problem. And the proxy layer turns out to solve more of it than most people realize, because it’s not just about rotating IPs. It’s about centralizing how your pipeline talks to the outside world before a single byte of data gets parsed.
Three Layers, One Flow
The architecture isn’t complicated when you strip it back. You’ve got an access layer in front, an ingestion buffer in the middle, and processing behind them.
The access layer is where proxy APIs sit. Every outbound request your pipeline makes, whether it’s hitting a REST endpoint or scraping a product page, goes through the proxy. One stable interface, regardless of what’s on the other side.
Behind that, the ingestion buffer catches raw data as it arrives. This can be an object storage bucket or a message queue like Kafka. Even a directory on disk works if you’re running lean. The point is to decouple extraction speed from processing speed. Your scrapers can run at full throttle while your parsers work through the backlog at their own pace.
Then comes the processing stage, where raw data gets normalized and validated before loading into whatever storage format your consumers need. That’s where multi-format parsing happens, and it’s where most pipelines get messy if you didn’t plan the layers ahead of it.
What the Proxy Layer Actually Handles
Most teams think of proxy APIs as an IP rotation tool and nothing more. That undersells what a well-configured proxy layer does for a data pipeline by a wide margin.
Secrets Stay Out of Your Pipeline Code
A proxy API stores API keys and OAuth tokens in a managed secret store and injects them into outbound requests server-side. Your pipeline jobs never see the actual credentials. They authenticate to the proxy using scoped service accounts with limited permissions, and the proxy handles the rest.
This matters more than it sounds. I’ve worked on projects where API keys were hardcoded in .env files across three different servers, and revoking access when someone left the team meant hunting through every deployment. With the proxy pattern, you rotate or revoke keys in one place and every pipeline job inherits the change immediately. One audit log covers all external calls, which makes compliance reviews a lot less painful.
Rotation and Session Control Per Job
Rotating proxy services typically offer two modes, and your pipeline needs both depending on the source.
Per-request rotation assigns a new IP to every outbound call. This is what you want for high-volume scraping where repeated requests from the same IP trigger blocks. Each request looks like a different user, and your scraper can run hundreds of concurrent connections without getting flagged. If you’re unsure which mode fits your use case, the static vs. rotating proxy comparison breaks it down well.
Sticky sessions keep the same IP for a configurable TTL across a sequence of requests. You need this for login flows, multi-step form submissions, or any target that expects consistent session state. The TTL should be tunable per job through the API, not locked to some dashboard default. A search page scrape might need a 30-second session, while a logged-in ecommerce flow might need 10 minutes.
Decodo handles both modes through API-level controls, which makes it a solid fit as the proxy infrastructure layer for pipeline work. You configure rotation behavior, geo-targeting, and protocol per request without touching dashboard settings.
Pulling Data from Three Different Worlds
Each source type comes with its own extraction pattern, and the proxy layer adapts to all of them.
REST and GraphQL endpoints get the cleanest treatment. Your pipeline calls the proxy with a logical resource URL, and the proxy injects credentials and adds pagination headers while handling rate-limit backoff. If the target API returns a 429, the proxy waits and retries before your pipeline even knows there was a problem. For multi-endpoint APIs, you can route by path suffix and HTTP verb so your pipeline code stays ignorant of which backend it’s actually hitting.
Web scraping is messier. Managed scraping APIs combine large IP pools with headless browser rendering and built-in anti-bot logic, all behind a single HTTPS endpoint. You send a URL, you get back rendered HTML or pre-parsed structured data. The Scrapy middleware pattern works well here: you fetch a proxy pool at init, assign a random proxy in process_request, and keep spider logic completely unaware of proxy details. Decodo’s scraping endpoint fits this pattern, returning clean data without requiring you to manage headless browser infrastructure yourself.
File-based feeds are the boring ones, but they’re also the sources that cause the most annoying bugs in production. Vendor CSV exports arrive with inconsistent delimiters and broken UTF-8 encoding. Column headers change without notice. XML feeds quietly switch namespace prefixes between versions. Fetch everything through the proxy, land it in raw storage, and let your downstream parsers deal with format specifics.
Making Five Formats Look Like One
Once raw data hits your ingestion buffer, the transform layer has to produce a consistent output from wildly inconsistent inputs. This is where sloppy architecture creates permanent headaches.
Format-Specific Parsing
JSON is usually the friendliest. Flatten nested objects and handle null fields with sensible defaults. Normalize types so that "42" and 42 don’t end up as two different data types in the same column. Watch out for APIs that return different JSON structures depending on whether a result set is empty.
CSV parsing needs explicit configuration on every import. Set the delimiter and quoting character explicitly, and don’t trust default encoding detection, because vendor defaults lie. Handle jagged rows (lines with more or fewer columns than the header) by logging them to an error table rather than silently dropping them. Enrich every row with file metadata like source path, byte offset, and import timestamp so you can trace problems back to specific files.
XML is the oldest and often the most fragile. Use XPath selectors to extract relevant elements into an intermediate JSON-like structure. Watch for namespace changes across feed versions, and don’t assume element ordering is stable.
Every parser should output to the same internal contract. In my pipelines, every record gets at minimum an id and a timestamp, plus a source_system field regardless of where it came from. That contract is what lets downstream consumers query across sources without caring about origin format.
Lock Your Schema Down Early
For new sources, I’ll use Spark’s .option("inferSchema", True) to get an initial read on field types. Then I disable inference permanently and pass an explicit schema from that point forward. Schema inference has a real performance cost, and it causes type inconsistencies across incremental batches. Your second import might infer a field as integer that the first import inferred as string, and now your pipeline is broken.
Raw layer gets schema-on-read. Curated layer gets strict schema-on-write. And if you’re writing to Parquet, sanitize field names before saving. Parquet doesn’t tolerate special characters in column names, and a feed with a field called price ($) will crash your writer without a useful error message.
Bronze, Silver, Gold
The medallion architecture maps naturally onto multi-format pipelines.
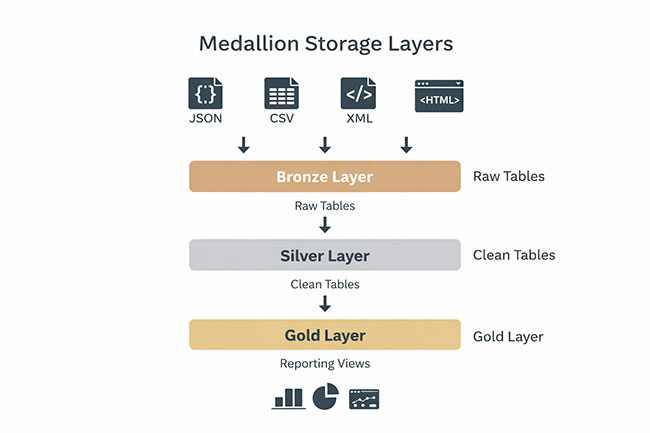
Bronze layer sits in object storage, partitioned by ingest date and source system. Raw data goes here in whatever format it arrived, from JSON blobs and CSV files to entire HTML dumps. You don’t transform anything at this stage. This layer exists so you can always go back and reprocess from scratch when your parsing logic changes or when a vendor quietly alters their export format.
Silver layer holds cleaned and conformed data in Delta Lake or Iceberg tables. Schemas are enforced, types are consistent, and deduplication has already happened. This is where your internal contract (id, timestamp, source_system) becomes mandatory.
Gold layer is built for the people who actually consume the data. Dashboards and ML feature stores pull from here, alongside domain-specific reporting tables. Everything here is optimized for read performance, and the structure matches business questions rather than source system quirks.
Error Handling and Proxy Health
For transient errors (502, 503, rate limit responses), use exponential backoff with jitter. The jitter part matters because without it, all your retrying workers slam the endpoint at the same time on every backoff interval. For permanent errors (4xx responses), don’t retry. Log and flag them, then move on. A dead-letter queue catches records that fail transform three times in a row, so you can investigate without blocking the rest of the pipeline.
On the proxy side, monitor success rate per endpoint, latency distribution, block rate, and pool health. Most proxy providers expose these metrics through their API. Pipe them into Prometheus and Grafana, or whatever observability stack your team already runs. When your scraper’s success rate drops from 98% to 85% overnight, you want to know before the business team asks why their dashboard is showing stale data.
Contract tests at the proxy boundary are worth the setup time. A simple check that verifies the response schema matches what your parser expects will catch upstream changes before they cascade through your pipeline.
How to Build a Multi-Format Data Pipeline with Proxy APIs








