

Google’s reCAPTCHA systems have become the frontline defense against automated traffic, but they remain far from infallible. Modern machine learning models can solve Google’s image challenges with approximately 70% accuracy, which explains why attackers constantly develop new bypass methods. Understanding how these systems detect suspicious activity is essential for security researchers and data collection professionals who need to work within ethical boundaries.
How Google reCAPTCHA Detection Works
Google deploys multiple reCAPTCHA variants, including the familiar checkbox challenges of v2 and the invisible scoring system of v3. Both versions analyze user behavior and technical signals to distinguish humans from bots.
Several factors trigger CAPTCHA challenges:
- IP Reputation: Addresses associated with prior scraping or abuse activity raise immediate flags. Shared datacenter IPs and known proxy nodes face heightened scrutiny.
- Browser Fingerprinting: Automation tools leave telltale signs. Missing plugins, abnormal screen resolutions, and the presence of the
navigator.webdriverflag all mark sessions as suspicious. - Behavioral Patterns: High-frequency requests without natural pauses, absence of mouse movement or scrolling, and stateless sessions lacking cookies signal non-human activity. reCAPTCHA v3 continuously scores these interactions.
- Rate Limiting: Sending too many queries too quickly triggers challenges or outright blocks. Google expects human users to read content between clicks.
- Geolocation Anomalies: Traffic from certain regions or through proxy networks faces more frequent verification requests.
The most effective approach focuses on avoiding CAPTCHAs entirely rather than solving them after they appear. Prevention beats remediation every time.
Effective Avoidance Techniques
Modern automation requires a multi-layered approach. Simple tricks like disabling obvious Selenium markers no longer suffice. Google aggressively detects standard automation frameworks and will force challenges after only a few automated searches, even with proxy rotation in place.
Choosing the Right Framework
Standard Selenium-driven browsers are easily detected. Security researchers recommend stealth-capable frameworks like Playwright or Puppeteer that allow low-level control over browser characteristics. These tools enable spoofing of fingerprint elements and simulation of human behavior patterns.
Some Google services respond differently to various approaches. Google Scholar and Google Finance, for instance, can sometimes be accessed with direct HTTP requests using Python’s requests library. Other services require headless browsers for reliable results.
Residential Proxy Rotation
High-quality rotating proxies mask a scraper’s origin effectively. Residential IP addresses with clean reputations appear as ordinary user traffic. Providers like Decodo offer large pools of residential IPs that rotate automatically, making it easier to distribute requests across multiple addresses. Rotating IPs every 1-20 requests prevents Google from associating too many queries with a single address.
Matching proxy geolocation to the target service matters significantly. A US-based IP for scraping Google US results appears more legitimate than traffic from an unexpected region. Monitoring for any IP that starts triggering CAPTCHAs and removing it from the pool maintains operational efficiency.
Behavioral Mimicry
Making automation behave like a human user dramatically reduces detection risk. This means simulating natural mouse movements with curved, variable-speed motions rather than robotic straight lines. Scrolling activity on pages should mirror how real users consume content.
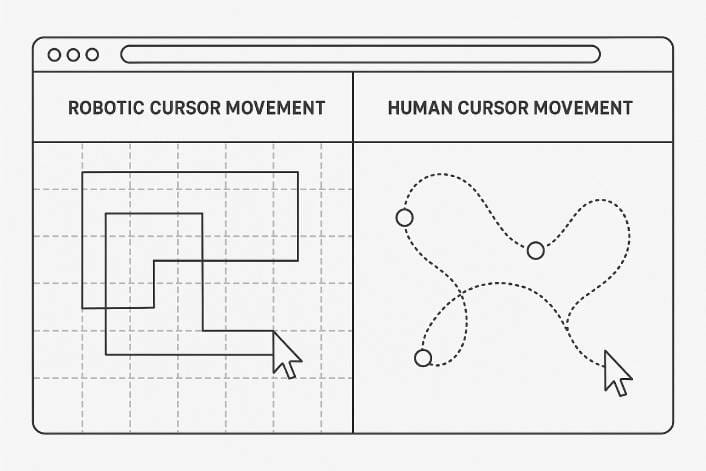
Typing patterns matter when entering search queries. Random delays, pauses, and occasional backspacing appear more natural than instantly pasted text. Adding random waits between page actions (2-8 seconds between navigations) mimics human reading time.
Session state preservation is equally important. Maintaining cookies and local storage across requests prevents each search from appearing as a fresh, suspicious session.
Browser Fingerprint Evasion
CAPTCHA defenses rely heavily on JavaScript fingerprinting to detect automation. Countering this requires rotating or spoofing common fingerprint elements:
- Varying user-agent strings to avoid always presenting a rare browser/version combination
- Randomizing browser viewport size and screen resolution
- Synchronizing reported timezone and language locale with proxy location
- Spoofing Canvas/WebGL graphics API outputs
- Emulating browser plugins that normal users would have
Modern tools like Playwright support these low-level modifications, including removing the navigator.webdriver flag and controlling navigator properties.
CAPTCHA Solving Services as Fallback
When challenges appear despite best efforts, third-party solving APIs provide a programmatic solution. Services like 2Captcha, Anti-Captcha, and CapSolver employ AI or human solvers to decode CAPTCHAs. Modern solvers claim 85-100% accuracy, often surpassing average human success rates.
Integration typically involves sending the CAPTCHA token or image to the service and receiving the solved result. This adds overhead and cost, making it a last resort for stuck scenarios. Using solving services keeps automated workflows running uninterrupted, though ethical considerations apply when solving CAPTCHAs in bulk.
Ethical Guidelines for Legitimate Use
Bypassing CAPTCHAs should only occur within legal and ethical boundaries. Security researchers testing systems or collecting data responsibly must adhere to these practices:
- Respect Robots.txt and Terms of Service: If a site disallows automated access to certain content, honor those rules. Ignoring explicit restrictions can result in IP bans and potential legal action.
- Access Only Public Data: Limit activities to openly available information without login or paywall requirements. Avoid attempting to bypass authentication or scrape personal data.
- Be Gentle on Services: Avoid overwhelming servers with excessive scraping. Use conservative request rates and consider operating during off-peak hours. Aggressive scraping can disrupt services, particularly for smaller sites.
- Maintain Attribution: When publishing or using scraped data externally, provide proper attribution to the source as required.
Technical Best Practices
Implementing solid technical practices improves success rates while maintaining ethical standards:
- Throttle and Backoff: Rate-limit requests to mimic human browsing speed. Keeping Google search queries to roughly one request per second and implementing exponential backoff when challenges appear reduces detection risk.
- Monitor Responses: Build monitoring to detect CAPTCHAs or blocks. Watch for HTTP status codes like 429 (Too Many Requests) or 403 (Forbidden), and text like “unusual traffic” in HTML responses. Upon detection, pause activity, switch proxies, or adjust strategy dynamically.
- Maintain Detailed Logs: Record timestamps, target URLs, proxy IPs, User-Agent strings, and cookies for each request. These logs prove invaluable for forensic analysis when Google flags activity, helping identify what triggered the CAPTCHA.
- Use Trusted Networks: Avoid open or untrusted proxy sources already known to Google. Premium proxy networks with minimal abuse provide fewer interruptions. Consider session persistence to reuse cookies on the same IP, mimicking a real user’s continued browsing.
- Plan for CAPTCHA Handling: Despite precautions, CAPTCHAs will occasionally appear. Integrating a solving API for important long-running tasks keeps data collection running hands-off when challenges arise.
- Leverage Official APIs: When Google provides sanctioned methods for needed data (such as the Custom Search JSON API), consider using them. Official APIs have usage quotas and costs but eliminate CAPTCHA concerns entirely while ensuring compliance.
Final Thoughts
Bypassing Google’s CAPTCHAs for security research or web scraping requires combining technical stealth with ethical restraint. Rather than cracking CAPTCHA tests directly, the consensus approach in 2025 emphasizes avoiding triggers through smart automation.
Using stealthy browsers instead of easily-detected frameworks, rotating through real-user IP addresses, behaving like genuine users, and varying browser fingerprints all contribute to successful data collection. Google’s CAPTCHA system detects non-human characteristics, and minimizing those signals remains the primary objective.
Conducting these efforts responsibly means respecting usage policies, scraping only allowable data, and backing off when detection thresholds are hit. With careful planning and a multi-layered approach, collecting data from Google reliably without encountering CAPTCHAs becomes achievable while staying compliant with both technical defenses and legal requirements.








